




What else can speech recognition do in the next decade?
Time:2021-12-15
Views:2410
从2010年到2020年的十年间,自动语音识别取得了显着进步。许多人现在每天都在使用语音识别,例如执行语音搜索查询、发送短信以及与语音助手进行交互。在2010年之前,大多数人很少使用语音识别。鉴于过去十年语音识别状态的显着变化,我们在未来十年可以期待什么?
Zoom杰出科学家,曾任职于Facebook和百度硅谷的Awni Hannun最近写了一篇论文预测未来十年语音识别技术的发展。在这篇论文中,作者首先回顾了过去十年(2010-2020)中,语音识别技术发展的时间线,接着给出了如何做预测的相关经验,最后预测了语音识别技术未来十年的研究热点和应用热点。
回顾
从2010年到2020年的十年间,语音识别和相关技术取得了显着进步。图1展示了过去十年中语音识别研究、软件和应用发展的时间线。这十年见证了基于手机的语音助手的推出和流行。亚马逊Alexa和Google Home等远场设备也已发布并大量涌现。
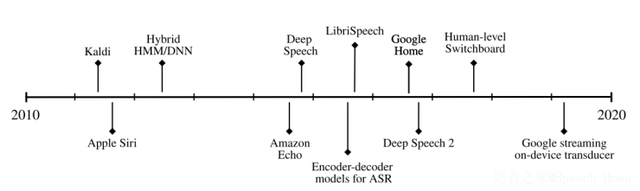
图1 语音识别技术在2010年到2020年之间的时间线
由于深度学习的兴起,自动语音识别的单词错误率显着降低,部分原因使得这些技术得以实现。深度学习在语音识别中取得成功的关键驱动因素是:1)海量转录数据集的管理;2)图形处理单元的快速进步;以及3)学习算法和模型架构的改进。
由于这些因素,语音识别器的单词错误率在整个十年中持续且显着改善。在两个最近的研究测试中,自动语音识别在单词错误率指标上已经击败了专业的转录员。
这一显著进展引发了一个问题:到2030年的未来十年还有什么可以做?下面,我尝试着回答这个问题。但是,在开始之前,我想首先分享一些关于预测未来这个一般问题的经验。这些灵感来自数学家(以及计算机科学家和电气工程师)Richard Hamming,他特别擅长
预测计算的未来。
关于预测未来的相关知识
Richard Hamming在《The Art of Doing Science and Engineering》中做出了许多预测,其中许多已经实现。这里有几个例子
他预测,“到2020年,由应用领域的专家来编写程序而不是让计算机专家将是相当普遍的做法。”
他预测神经网络“代表了编程问题的解决方案”,并且“它们可能会在计算机的未来发挥重要作用。”
他预测了通用而非专用硬件、模拟数字和高级编程语言的流行。
早在交换机实际发生之前,他就预计使用光纤电缆代替铜线进行通信。
关于技术预测的一个普遍说法是,短期预测往往过于乐观,而长期预测往往过于悲观。这通常归因于技术进步呈指数级增长的事实。图2显示了如果我们从当前假设来看,进展与时间呈线性关系的乐观推断。过去十年(2010‑2020年)语音识别的进步是由两个关键轴上的指数增长推动的。分别是计算(例如每秒浮点操作)和数据集大小。图2是否适用于未来十年的语音识别还有待观察。

图2 进展与时间的关系
我相信下面的很多预测都会被证明是错误的。在某些方面,尤其是在涉及更具争议性的预测时,这些确实更像是对未来的愿望清单。关于这一点,让我用计算机科学家Alan Kay的名言结束本段:预测未来最好的方法就是去创造它。
研究方向的预测
半监督学习
预测:半监督学习将继续存在。特别是,自我监督的预训练模型将成为许多机器学习应用程序的一部分,包括语音识别。
作为研究科学家,我的部分工作是招聘,这意味着要进行大量面试。我已经面试了一百多名从事各种机器学习应用程序的候选人。很大一部分人,尤其是自然语言应用程序,依赖预训练模型作为其支持机器学习的产品或功能的基础。自监督预训练已经在工业应用中普遍存在。我预测到2030年,自我监督的预训练将在语音识别中同样普遍。
过去三年的深度学习是半监督和自我监督的年份。该领域无疑已经学会了如何使用未注释的数据改进机器学习模型。自监督学习已经使许多最具挑战性的机器学习任务受益。在语言任务中,最先进的转录已经被自我监督模型超越。自监督和半监督现在很常见,并在计算机视觉和机器翻译中创下了记录。
语音识别也受益于半监督学习。第一种方法是自监督预训练,其损失函数基于对比预测编码。这个想法很简单:训练模型来预测给定过去音频的未来帧。第二种方法是伪标记。同样,这个想法很简单:使用经过训练的模型来预测未标记数据的标签,然后在预测的标签上训练一个新模型。伪标签起作用的原因和机制是有趣的研究问题。
自我监督的主要挑战是规模和泛化性能。目前只有最顶级的行业研究实验室有资金大规模地进行监督训练。作为一个研究方向,监督学习是大多数实验室和业界不太容易接近的。
研究意义:考虑到可以在更少数据上进行有效训练的轻量级模型,自监督学习将更容易实现。相关的研究方向包括轻量级模型的稀疏性、更快训练的优化以及结合先验知识以提高样本效率的有效方法。
边缘计算
预测:大多数语音识别将在设备端或移动边缘进行。
这个预测有几个原因。首先,将数据保存在设备上而不是将其发送到中央服务器更加私密。数据隐私的趋势将带来设备端的计算需求。如果模型需要从用户的数据中学习,那么训练应该在设备上进行。
首选边缘计算的第二个原因是延迟。从绝对值来看,10毫秒和100毫秒之间的差异并不大。但前者远低于人类的感知延迟,后者则远高于。谷歌已经展示了一种在设备上进行的语音识别系统,其准确度几乎与良好的服务器端口系统一致。从实用的角度来看,设备上系统难以察觉的延迟使得与设备的交互感觉更加灵敏,因此更具吸引力。
最后一个原因是100%的可用性。即使没有互联网连接或不稳定的服务,识别器也能工作,这意味着它会一直工作。从用户交互的角度来看,大部分时间都有效的产品和每次都有效的产品之间存在很大差异。
研究意义:设备上识别需要计算量小、功耗低的模型。模型量化和知识蒸馏(训练较小的模型以模拟更准确的较大模型)是两种常用的技术。不太常用的稀疏性是另一种生成轻量级模型的方法。在稀疏模型中,大部分参数(即隐藏状态之间的连接)为零,可以有效地忽略。在这三种技术中,我认为稀疏性是最有前途的研究方向。
我相信我们已经挖掘了量化的最大价值,即使在不太可能的情况下将量化从 8 位进一步减少到 1 位,我们只能获得八倍的增益。对于蒸馏,我们还有很多东西要学。但是,我相信揭示蒸馏工作的机制将使我们能够直接训练小模型,而不是走迂回的路线,先训练大模型,然后再训练第二个小模型来模仿大模型。
这使得稀疏性成为轻量级模型最有前途的研究方向。正如“彩票假设”之类的发现所证明的那样,我们关于稀疏性在深度学习中的作用有很多需要了解。从理论上讲,稀疏性带来的计算收益可能是巨大的。实现这些收益将需要开发用于评估稀疏模型的软件,可能还有硬件。
字错误率
预测:到30年,可能更早,研究人员将不再发表类似于“使用模型架构Y提高基准X上的单词错误率”的论文。
正如您在图3中看到的,两个最常研究的语音识别基准的单词错误率已经饱和。部分问题是我们需要更严格的基准供研究人员研究。最近发布的两个基准可能会刺激语音识别领域的进一步研究。但是,我预测这些基准会随着模型和计算的扩展而迅速饱和。

图3 两个数据集上的字错误率
问题的另一部分是,我们已经来到了一个境况,即学术基准上的单词错误率改进不再与实用价值相关。几年前,图3中两个基准的语音识别单词错误率打败了了人类的单词错误率。然而,在大多数情况下,人类比机器更能理解语音。这意味着单词错误率作为我们语音识别系统质量的衡量标准与理解人类语音的能力没有很好的相关性。
最后一个问题是,随着模型和数据集越来越大,以及计算成本的增加,最先进的语音识别研究变得越来越难以获得。一些资金充足的工业实验室正迅速成为唯一可以进行此类研究的地方。随着进步变得越来越慢,离学术界也越来越远,这部分领域将继续从研究实验室转向工程组织。
更丰富的表达
预测:对于依赖语音识别器输出的下游任务,转录将被更丰富的表达所取代。此类下游应用程序的示例包括对话代理、基于语音的搜索查询和数字助理。
下游应用程序通常不关心逐字转录;他们关心语义正确性。因此,提高语音识别器的单词错误率通常不会提高下游任务的目标。一种可能性是开发一个语义错误率并用它来衡量语音识别器的质量。这是一个具有挑战性但有趣的研究问题。
我认为更有可能的结果是通过语音识别器为下游应用程序提供更丰富的表达形式。例如,不是传递单个转录,而是传递捕获每个可能性的不确定性的网格(如图4所示)可能更有用。
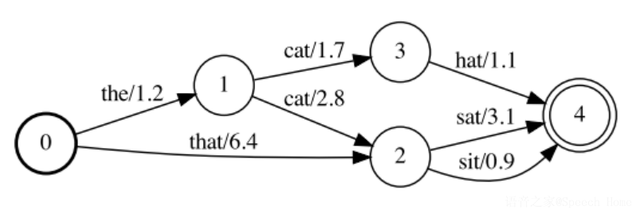
图4 一个基于语音识别加权的编码网格示例
个性化
预测:到2030年,语音识别模型将针对个人用户进行深度个性化。
语音的自动识别与人类对语音的解释之间的主要区别之一在于上下文的使用。人类在相互交谈时会依赖很多上下文信息。此上下文包括对话主题、过去所说的内容、噪音背景以及唇部运动和面部表情等视觉线索。对于断章取义的简短话语(即长度小于10秒),我们已经或即将达到语音识别的最优错误率。我们的模型正在尽其所能使用数据中可用的信息。为了继续提高机器对人类语音的理解,需要将上下文作为识别过程的更深层次的一部分。
做到这一点的一种方法是个性化。针对患有语言障碍的个人用户的个性化模型将单词错误率改善了64%。个性化可以对识别质量产生巨大影响,特别是对于在训练数据中代表性不足的群体或领域。我预测到2030年,我们将看到更加普遍的个性化。
研究意义:设备上的个性化需要在本地进行的训练,这本身就需要轻量级的模型和某种形式的弱监督。个性化需要可以根据给定用户或上下文轻松定制的模型。将此类上下文纳入模型的最佳方法仍然是一个研究问题。
应用预测
转录服务
预测:到2030年,99%的转录语音服务将通过自动语音识别来完成。人工转录员将执行质量控制并纠正或转录更困难的话语。转录服务包括例如为视频添加字幕、转录采访以及转录讲座或演讲。
语音助手
预测:语音助手会变得更好,但是需要一个过程。语音识别不再是更好的语音助手的瓶颈。瓶颈现在完全在语言理解领域,包括保持对话的能力、多重上下文响应以及更广泛的领域问答。我们将继续在这些所谓的AI‑complete问题上取得进展,但我不认为它们会在2030年得到解决。
我们是否会生活在智能家居中,始终倾听并响应我们的每一个声音?
我们会佩戴增强现实眼镜并用声音控制它们?
到2030年不会。
结论
这些预测表明,未来十年对于语音识别和口语理解的发展可能与前十年一样令人兴奋和重要。在语音识别达到对每个人来说一直有效的状态之前,我们还有许多研究问题需要解决。然而,这是一个值得努力的目标,因为语音识别技术是进行更流畅、更自然交互的关键组成部分。
|
免责声明: 本文章转自其它平台,并不代表本站观点及立场。若有侵权或异议,请联系我们删除。谢谢! |





 Business consulting
Business consulting

 13823761625
13823761625 Mail me
Mail me