




如何在ADI DSP中设计一个合理的混响?
发布日期:2024-02-01
点击次数:340
作者:Terry Yuan
摘要:本文围绕对混响的需求、原理以及实现流程展开详细描述,一方面可以帮助大家了解混响效果的一些基本知识,另一方面工程师可以参考这些模型用到自己的产品上,从而设计出比较贴合自身产品的算法。
DSP混响的需求来源
声波在室内传播时,会被墙壁、天花板、地板等障碍物反射,每经过反射一次都会被障碍物吸收一些。当声源停止发声后,声波在室内要经过多次反射和吸收,最后才消失。因此我们可以感觉到,当声源停止发声后还有若干个声波混合持续一段时间,即室内声源停止发声后仍然存在的声延续现象,这种现象叫做混响,这段时间叫做混响时间。
在演奏表演时,为了获取一个高质量的音乐效果,混响是极为重要的组成部分。随着目前声学相关设备的需求量越来越高,大家对音乐中的声音质感要求也越来越高。在混响上主要的实现方式包括物理模拟、采样混响以及人工混响三种方式,物理模拟因为计算量巨大,在实际场景落地比较困难,用的极少。采样混响实现简单,但是灵活度不够,种类也比较少。而人工混响计算量小、实现简单,所以在实际应用上比较广泛,当然缺点就是不如前两种逼真,但是支持普通的调音、混音、演奏需求是完全没有问题的。下面将介绍混响在DSP中的概念、应用及其实现。
DSP混响的定义及优点
DSP混响(Digital Signal Processing Reverb)是一种使用数字信号处理技术(DSP)来实现混响效果的技术。混响是指声波在室内或其他封闭空间内反射、散射和衰减的现象,它可以使声音更具空间感、深度和宽度。在音频处理和音乐制作中,混响效果非常重要,它可以让声音更加自然、丰富和立体。它具有以下几种优点:
• 灵活性:可轻松调整改变混响参数,如延迟时间、衰减率、房间大小等,适应不同应用场景。
• 实时处理:通过实时处理技术,对音频信号进行实时处理,从而实现混响效果。
• 高质量:可提供高质量的混响效果,使声音更加自然和真实。
• 节省资源:可节省宝贵的音频处理资源,如CPU、内存等。
总之,DSP混响在音乐制作、录音、广播、游戏、电影等领域有着广泛的应用,通过DSP混响技术,我们可以创造出更加丰富、立体和自然的声音效果。 说到混响,我们还需要知道的一个概念就是回声。回声是在一个方向的延迟反射,而混响则是在多个方向的多次延迟反射。在软件混响原理中我们能看到的基本上分为以下三种类型:
• 回声类:以多回声构建的echos系统,回声数量由自身根据具体类型进行控制。
• 脉冲响应类(IR 类):多见于现场采集各种模型,通过与后音源做卷积来得到较好的输出效果。
• Schroeder & Moorer类:它是一种混合模型结构。
对于目前市面上主流的一些混响种类,比如房间混响、大厅混响、板式混响、教堂混响、弹簧混响等等,其实现原理都可以用上面三类方式来进行实现。目前我们常见这些混响种类,在调音师或者混音师的工程里,主要用于提升特殊效果,增加音乐的氛围感、空间感和立体感。
ECHO类混响系统
谈及回声类混响系统,这里不得不提到Comb Filter混响器,简单理解就是声音在空间中不断碰撞并产生回声的一个过程。同理,在播放器端,我们需要播放的其实就是一个音源,以及它被无数次后续回声追加的一个过程,简称梳状滤波混响器。这里我们需要建立一个数学模型,下图(图1)为一个简单的房间混响模型表示:
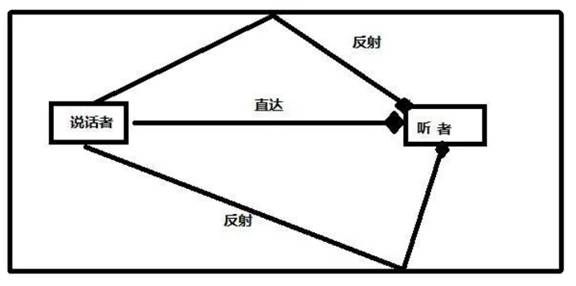
图1 房间声音模型
从图中可以看出,房子的反射效果受房间大小以及反射强度影响。如果房间足够大、吸音材料非常好,就会导致房间内基本上没什么反射。反之反射就会比较强烈。在房间建筑学设计中,比较多通过塞宾公式来进行估算,而混响强度的标准一般以RT60为主。参考该物理模型,我们在梳状滤波器的设计过程中就可以进行一系列的公式推导,例如:
假设说话者说出的信号是x[n],听者某时刻接收到的信号是y[n],那么y[n]包含那些内容呢?
y[n] 应该是 x[n] + 反射1 + 反射2 .......
反射怎么表示?它应该是x[n] 的延时。我们假设延时m ,那么反射1 应该是 x[n-m] ,但是我们还应该考虑反射时的衰减,也就是上面所说的房子的反射效果。假设衰减是a,则反射1 应该表示成 x[n -m]*a
所以,y[n] = x[n] + a*x[n-m] + a^2*x[n- 2m] + a^3*x[n- 3m]......
简化下求和,利用差分或者z变化可以得到差分方程:y[n] = ay[n-m] + x[n]
通过以上公式推导,可以得到如下图(图2)所示的该模型结构图以及时域和频域表现。
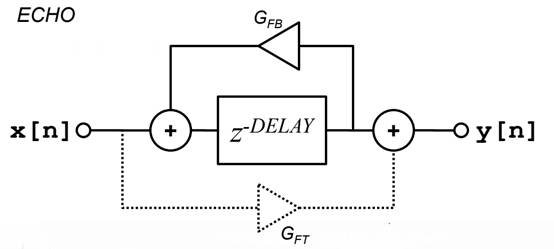
图2 模型块状图
在时域上,作为一个等比例(反馈衰减系数取决于自身设计的衰减公式)衰减模型,其呈现一种周期性递减规律,如下图(图3)所示:

图3 单位冲击响应随时间的变化
在频域上,系统对频率具有周期响应,且具备最大值与最小值,这样我们将会得到像梳子一样的波形图,如下图(图4)所示,因此也被称为梳状滤波器。
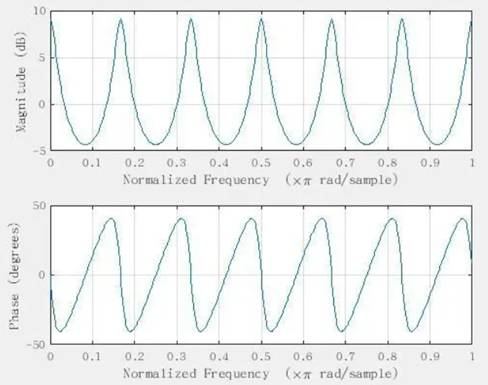

图4 频谱以及相位表现图
由此,我们就可以根据这样一个模型去设计一个简单的算法,在DSP芯片中,它的算力不是很高,存储空间不是很大,但有时候在我们需要选取一点点回声类混响系统里比较好用的产品时,例如一些轻量级的低功耗电子产品,需要有一点混响的镶边效果,我们就可以用这种方式去实现。而对于另外那些较高标准、功耗不敏感的产品,我们使用以下介绍的两种方式实现效果将会更好。
IR类混响系统
对于模拟现实生活的中混响,试想一下,如果我们在一个房间里面对面地交谈,因为声音在房间里面的反射是无处不在的,在开始沟通的过程中,会有最开始的一部分直达声进入我们的耳朵,这时它的能量是最高的。随后通过各种各样的反射,声音的能量得到衰减后慢慢进入到我们的耳朵,这个时间和能量的表现就像是一个个脉冲,所以在这里描述它就是脉冲响应类的其中一种混响。那么在实现上,如何达到这种接近现实的混响效果呢?
在计算机领域里,我们很多时候是根据不同的混响特征来生成IR文件,也可以根据录制等方式去获取特定的空间混响。因为有一些混响,在算法的实现上十分困难,且具备一定的特异条件,但是当我们又需要到这种混响背景的时候就需要用到它了。
在实现上,我们通常通过特定的IR文件和原始音源来进行卷积运算,而卷积的计算公式和方式比较复杂,为了方便大家理解,可以想象是把输入的信号和IR进行乘法运算,从而达到使输入的信号里面有IR的混响效果。
在DSP的实现上,类比我们经常能够在一些上位机软件中看到的特征混响,这些IR文件将以各种方式存储在我们的Flash内,并且可能具备多个model1、model2、model3等等。取特定文件出来,在DSP内部进行卷积运算输出即可,这多见于一些音乐设备中特定类型的混响。
Schroeder & Moorer类混响系统
上文提及的ECHO类混响,在梳状滤波器设计完毕后,会存在一些不完美的地方。其实从幅度谱以及相位谱就能看出来,幅度谱不是足够平坦,这样在共振峰和瞬态比较大的条件下,它所带来的声音表现着色非常严重,相位的变化也不恒定。因此Schroeder对混响进行了大量的改良技术,在 “Colorless” Artificial Reverberation – 1961和Natural Sounding Artificial Reverberation – 1962的2篇论文中有提到该技术。针对回波密度不够的表现,增加了多组梳状滤波器的并联组合,同时加入了全通滤波器。因为全通滤波器的频谱就是一条直线,不对任何频率产生影响,且仅仅只是附带一些群延时的效果,这样就可以用来实现消除强烈着色的效果。同时因为回声密度的增加,将使得系统更加趋近于真实的效果,如下图(图5)所示:
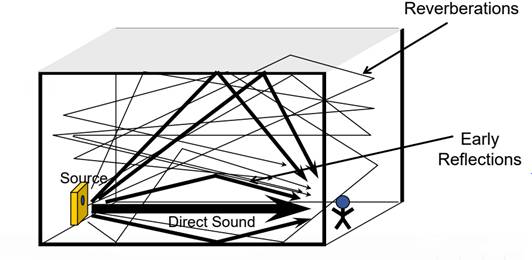
图5 真实混响模型图
其脉冲响应大概可以描述成如下图(图6)所示的图形:
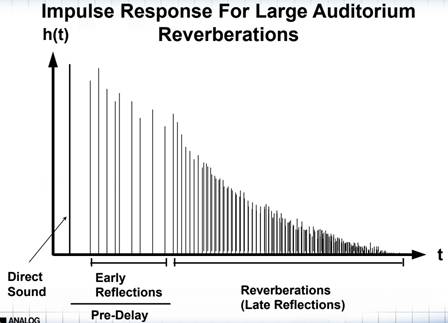
图6 脉冲响应模型图
其模型块状图如下图(图7)所示:
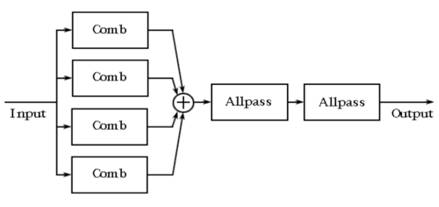
图7 Schroeder脉冲响应模型图
从上图模型不难看出,四个梳状滤波器的叠加会使我们大大增加回声密度,从而弥补了ECHO类回声密度过于稀少的问题。在Schroeder的观念里,每秒的回声至少要达到1000个才能基本符合,且每个回声的延迟不能一样,一样就会导致4个梳状滤波器制造的回声时域上的一致,这样就失去其意义。做完梳状滤波器的叠加后,通过连接2个全通滤波器做乘法运算,在进一步增加回声密度的同时减少金属音。
在Comb的参数选择上,延时的比例一般选在1:1.5,尽量选择没有公因数的延迟时间,有公因数会导致某些地方的重叠,并且合理地设计好G(衰减系数)的大小,一般都是根据D值和RT60进行计算,确保大小是在一个比较合理的范围。在全通滤波器的选择上,延时尽可能要低(1-5ms),增益值在0.5-0.77之间会比较合适。
Schroeder混响的算法相对而言比较简单,而且也能达到一个非常不错的效果。但是随着后来的发展,Schroeder算法也存在一些可以改进的点,例如上图(图6)的预梳理和预延时模块,如果想获取更加逼真的效果,在早期反射其实不能够完全按照Schroeder模型进行设计,要增加APF以及Pre-delay模块,或者可以考虑是否可以增加更加多的Comb来获取更多的回声密度、后端的APF是否可以嵌套使用等等。在Schroeder的基础之上,Moorer的数字混响模型也就诞生了,下图(图8)为Moorer脉冲响应模型图:
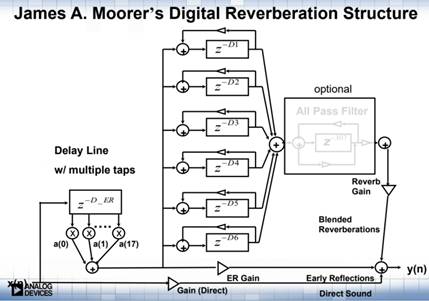
图8 Moorer脉冲响应模型图
Moorer算法模型大概将一个混响分成了三个阶段:直达声、早期混响、晚期混响。早期混响通过增加前级反馈和FIR来模拟,同时增加低通滤波器来模拟高通在空气中的衰减效果,后端增加到6个Comb组以及APF的嵌套使用。
随着目前大家对音频相关产品的需求增加,混响对于音频设备来说已经成为一种基本需求。那么在混响中又有哪些参数调整?在ADI的DSP中我们该如何选择DSP去设计一套合理的算法?接下来将对混响的具体参数调整以及选择ADI的DSP设计合理算法进行深入解析。
混响的常见参数
目前做一个专业级的混响需要设置许多的参数,有些参数是必备的,而有些是特定的需求下慢慢增加起的。专业的效果器一般包含如下图(图9)的一些参数:
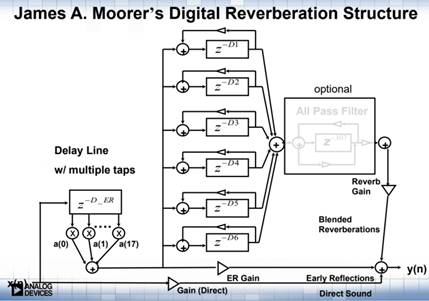
图9 混响的相关参数
• 混响时间:能够逼真地模拟自然混响的数码混响器上都有一套复杂的程序,其中虽然有很多技术参数可调,然而对这些技术参数的调整都不会比原有的效果更为自然,尤其是混响时间(取决于预延迟时间,以及衰减速率和收敛的判定)。
• 预延迟时间:在混响效果器上的众多参数中,预延迟时间(Predelay)是一个比较重要的点。所谓的预延迟时间,指的是达到人耳的直达声和第一次反射声之间的时间间隔。在混音中,预延迟时间的选择是与我们的基准时间有着一定的关联性的。而基准时间的计算方式一般来说就是拿60秒除以音乐BPM的值(取决于直达声之后做的延迟时间以及FIR的时间)。
• 高频滚降:此项参数用于模拟自然混响当中,空气对高频的吸收效应,以产生较为自然的混响效果。一般高频混降的可调范围为0.1~1.0。此值较高时,混响效果也较接近自然混响;此值较低时,混响效果则较清澈(取决于低通滤波器的阶数以及截至频率的设计)。
• 扩散度:此项参数可调整混响声阵密度的增长速度,其可调范围为0~10,其值较高时,混响效果比较丰厚、温暖;其值较低时,混响效果则较空旷、冷僻(取决于Comb Filter的D值选取以及回声密度递增数值)。
• 声阵密度:此项参数可调整声阵的密度,其值较高时,混响效果较为温暖,但有明显的声染色;其值较低时,混响效果较深邃,切声染色也较弱(取决于Comb Filter的数量)。
• 频率调制:这是一项技术性的参数,因为电子混响的声阵密度比自然混响稀疏,为了使混响的声音比较平滑、连贯,需要对混响声阵列的延时时间进行调制。此项技术可以有效地消除延时声阵列的段裂声,可以增加混响声的柔和感(取决于Comb Filter的延时时间)。
• 混响类型:不同房间的自然混响声阵列差别也较大,而这种差别也不是一两项参数就能表现的。在数码混响器当中,不同的自然混响需要不同的程序。其可选项一般有小厅(S-Hall)、大厅(L-Hall)、房间(Room)、随机(Random)、反混响(Reverse)、钢板(Plate)、弹簧(Spring)等。其中小厅、大厅房间混响属自然混响效果;钢板、弹簧混响则可以模拟早期机械式混响的处理效果。
• 干湿比:干声信号和混响信号的比例,调节直达声以及混响信号的分量比重。
从这些后续发展出来的参数不难看出,涉及的调节选择变得越来越多,那么对于设计者来讲如何挑选合适的参数和类型去搭建自己想要的产品就变得非常重要。
DSP和混响类型的选择
在实际的生产应用中,选择混响的类型,并不是直接去选一个最完善的类型就好了。实际上很多时候应用达不到这个条件,越完善的混响类型意味着对DSP的内存空间的需求以及算力的大小都是有需求的,然而很多成本预算不是那么充足,或者工作环境对功耗等等方面都有需求的产品,我们是无法选择那么一个比较高复杂度的混响。
举个很简单的例子,比如A客户需要做一个轻量级的吉他拾音器,拾音器主要的目的就是拾音,当然为了丰富一些效果,可能我们需要调节高中低频的EQ,加一个混响,在这个时候,选择一个ECHO类的混响要比选择MOORER类的混响好太多。从控制成本和功耗的角度上来讲,虽然ECHO类并不如Moorer类的好,但是在演奏中已经够用,复杂的可以通过拾取后,送到效果器或者功放中去实现。
在选择时,建议都要根据自己的产品类型合理地从成本、封装体积大小,以及功耗上选择最为合适的产品。
ADI DSP在ECHO类算法的基本实现
众所周知,ADI在音频的DSP上相当有竞争力,从其Sigma到Sharc 类的DSP均用到了各类的音频电子产品中。如下图(图10)所示为ADI SigmaDSP产品选型对比表:

图10 SigmaDSP的产品选型对比表
下图(图11)为ADI Sharc DSP产品选型对比表:
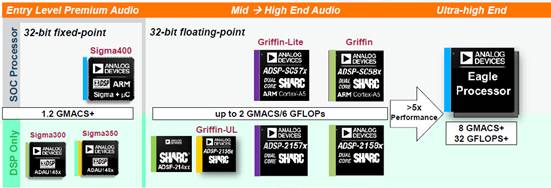
图11 SharcDSP的产品选型对比表
ADI SigmaDSP的产品是定点的数字信号处理器,而SharcDSP即全浮点的数字信号处理器。全浮点的DSP可以处理复杂度比较高的混响,SigmaDSP一般用于处理一些简单一点的混响。以下将展示一些ECHO类混响在DSP上的应用实现,目前混响主要对内存的空间需求是比较多的,存在着很多Delay。
在ADAU1701和ADAU1761中的实现:
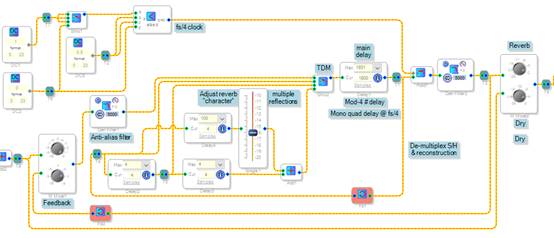
图12 ECHO类混响在ADAU1761中的实现
从上图(图12)可以看出,直达声直接作为干音传到输出端,将音源的左右通达合成一路用来减少内存空间和算力的消耗,用三个延时线创造混响空间,传到后端进行低通滤波,实现高频滚降。这样做能够得到一定量的混响的效果,但是回声密度不够,增益调节以及扩散度和频率调制是无法实现的,适合一些轻量化的产品应用。我们在SharcDSP中一般直接通过代码来实现,例如下方的ECHO类回声的实现:
创建一个DSP混响的效果器。以下图(13)是一个使用Python和NumPy库实现的简单DSP混响效果的示例代码:
图13 Python实现DSP混响效果(横版)
如上图(图13)所示的代码实现了一个基本的DSP混响效果,包括延迟线和低通滤波器。我们可以根据需要调整延迟时间和截止频率来改变混响的效果。需要注意的是,这个示例使用了Python的NumPy库来处理数字信号,并且需要在支持音频播放的环境中运行(例如Jupyter notebook或Python脚本)。

图14 ECHO类混响效果用C语言实现(横版)
如上图(图14)所示的代码是一个简单的DSP混响效果实现,它使用了C语言进行编程。代码主要有以下操作:
• 定义了一些常量,如采样率、帧大小、通道数、延迟长度和衰减时间等;
• 定义了一个名为DelayBuffer的结构体,用于实现延迟缓冲区;
• 创建了一个名为create_delay_buffer的函数,用于创建延迟缓冲区;
• 定义了一个名为destroy_delay_buffer的函数,用于销毁延迟缓冲区。
在main函数中,首先创建了一个延迟缓冲区,然后进入了一个循环,模拟了信号的输入、处理和输出过程。在每次循环中,信号被输入到混响效果处理中,处理后的信号被输出。同时,衰减时间也在不断衰减。最后,当延迟时间达到最大值时,循环结束,延迟缓冲区被销毁。在我们的Sharc 平台上,当我们跑通Framework之后,导入这一部分代码,将音频流导入进去就可以得到一个ECHO类的混响效果。
如果需要更高级好用的Schroeder & Moorer类混响系统时,可以通过开源框架Sox,Freeverb和Tonic去获取,完整的算法会比较长,需要大家在线下去参考。
总结
本文围绕对混响的需求、原理以及实现流程展开详细描述,一方面可以帮助大家了解混响效果的一些基本知识,另一方面工程师可以参考这些模型用到自己的产品上,从而设计出比较贴合自身产品的算法。
|
免责声明: 本文章转自其它平台,并不代表本站观点及立场。若有侵权或异议,请联系我们删除。谢谢! |





 发送邮件
发送邮件 商务QQ客服
商务QQ客服 13823761625
13823761625

